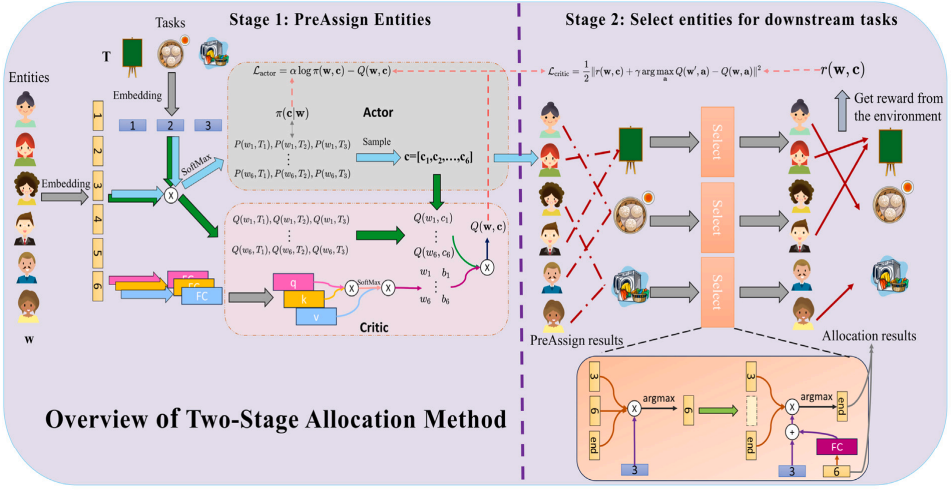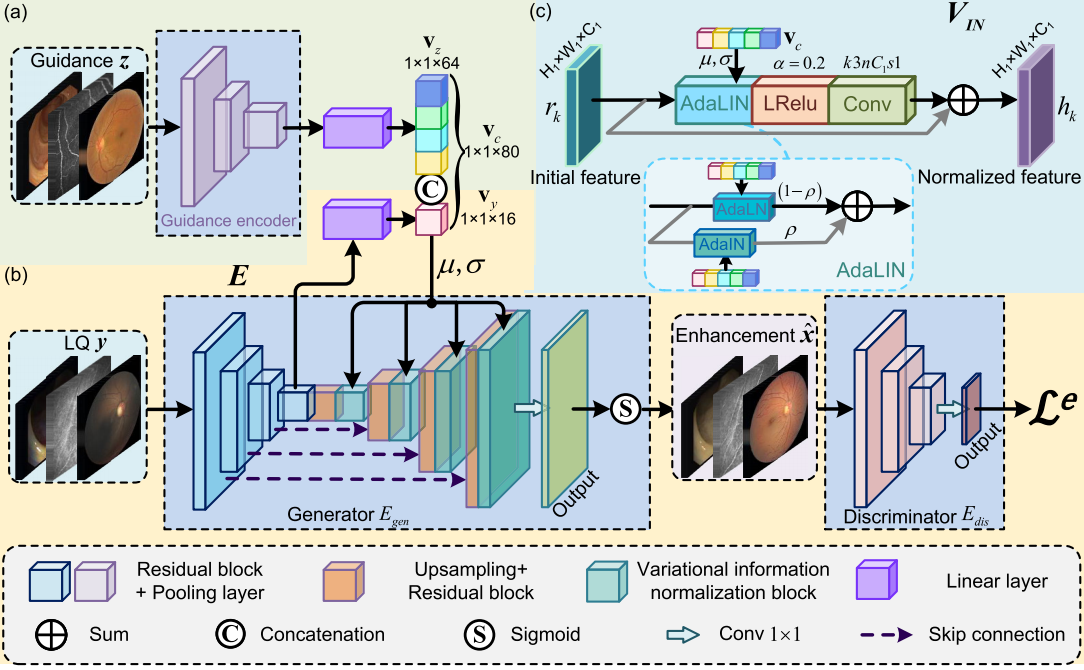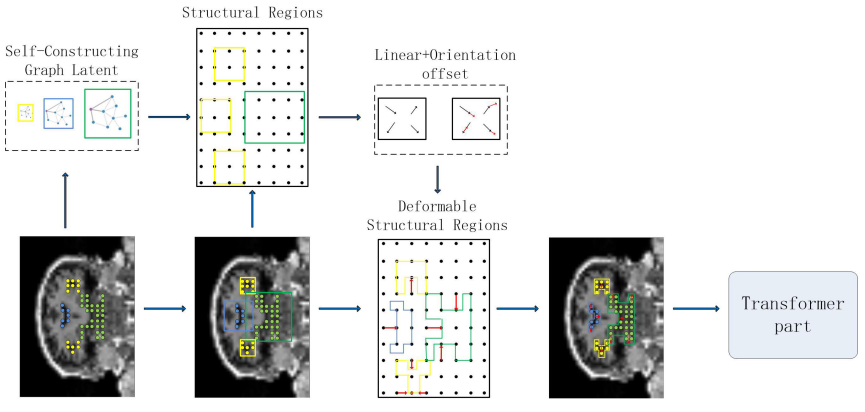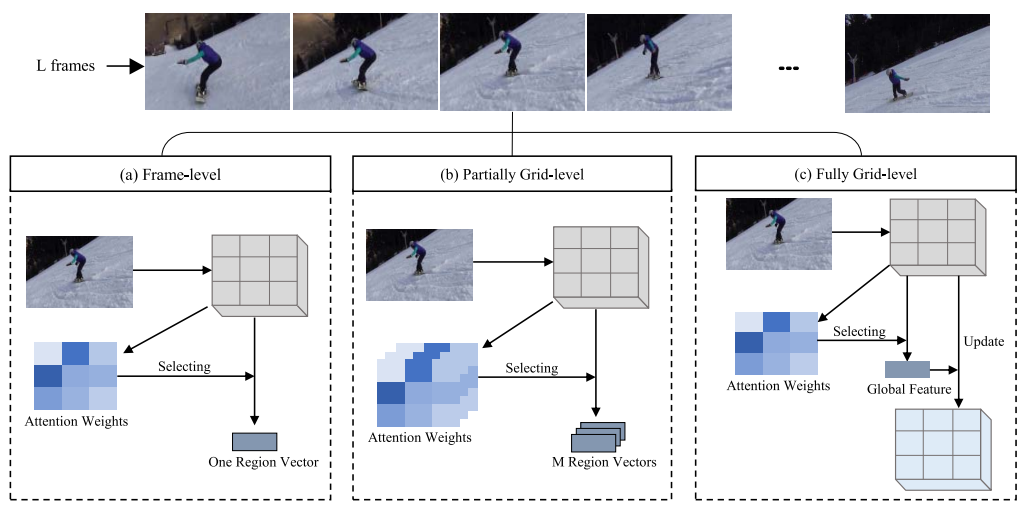
|
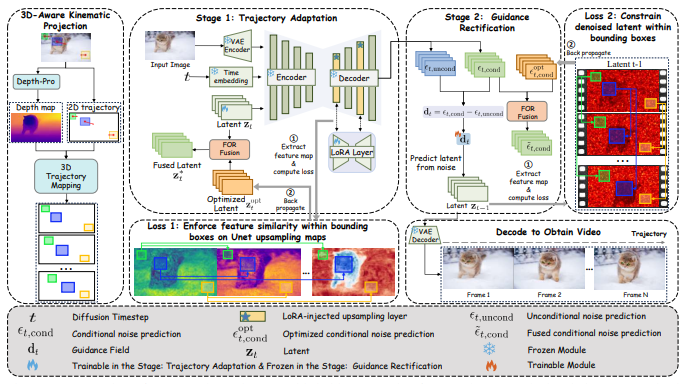
- Ruicheng Zhang*, Jun Zhou*†, Zunnan Xu*, Zihao Liu, Jiehui Huang, Mingyang Zhang, Yu Sun, Xiu Li†. Zo3T: Zero-Shot 3D-Aware Trajectory-Guided Image-to-Video Generation via Test-Time Training[C]. In The Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI), 2025.
[Page]
|
|
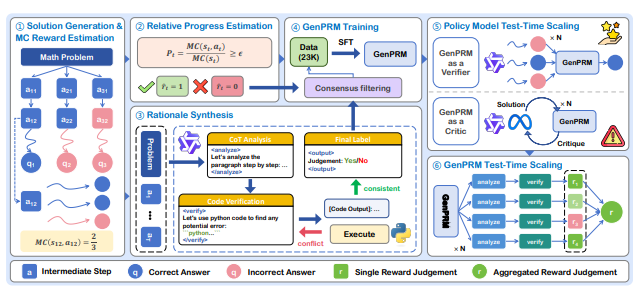
- Jian Zhao*, Runze Liu*, Kaiyan Zhang, Zhimu Zhou, Junqi Gao, Dong Li, Jiafei Lyu, Zhouyi Qian, Biqing Qi†, Xiu Li†, Bowen Zhou†. GenPRM: Scaling Test-Time Compute of Process Reward Models via Generative Reasoning[C]. In The Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI), 2025.
[Page]
|
|
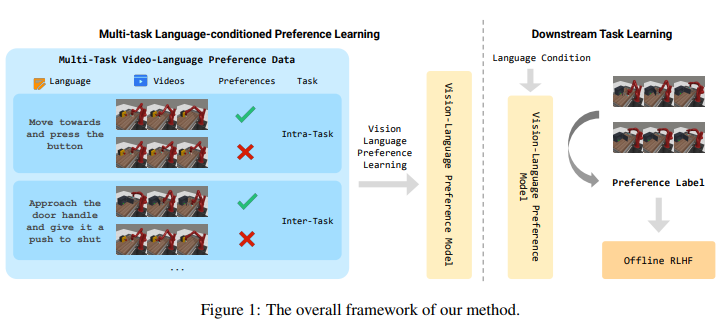
- Runze Liu, Chenjia Bai†, Jiafei Lyu, Shengjie Sun, Yali Du, and Xiu Li†. VLP: Vision-Language Preference Learning for Embodied Manipulation[C]. Proceedings of the 2025 Conference on Empirical Methods in Natural Language Processing(EMNLP), 2025: 28428-28444.
[Page]
|

|
- Y Lin*, N Huang*, K Huang, H Liu, Y Yan, J Guo, TY Lee, X Li†. ICE: Intercede Concept Erasure in Text-to-Image Diffusion Models[C]. Proceedings of the 33rd ACM International Conference on Multimedia, 2025: 11328-11336. WOS:001671135600396. EI Accession number: 20255019681979
[Page]
|
|
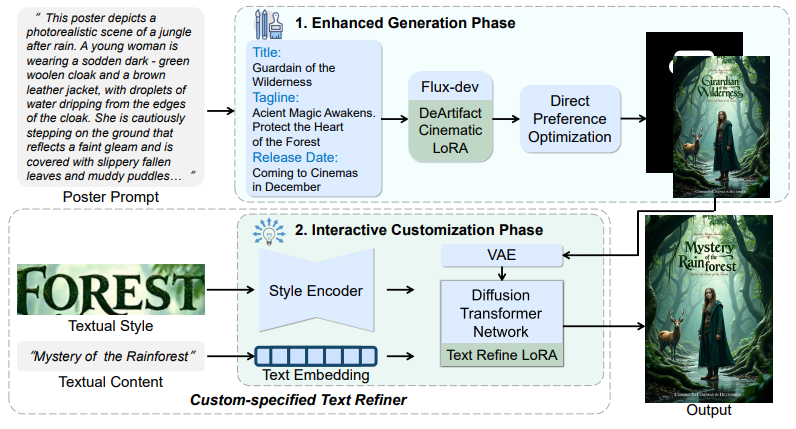
- X Fu, N Huang†, J Li, J Guo, X Li†, TY Lee. PolyArt: Customizable Multilingual Movie Poster Generation via Diffusion Transformer[C]. ACM SIGGRAPH Asia Posters, 2025.WOS:001695183600010. EI Accession number: 20260720068461
[Page]
|
|
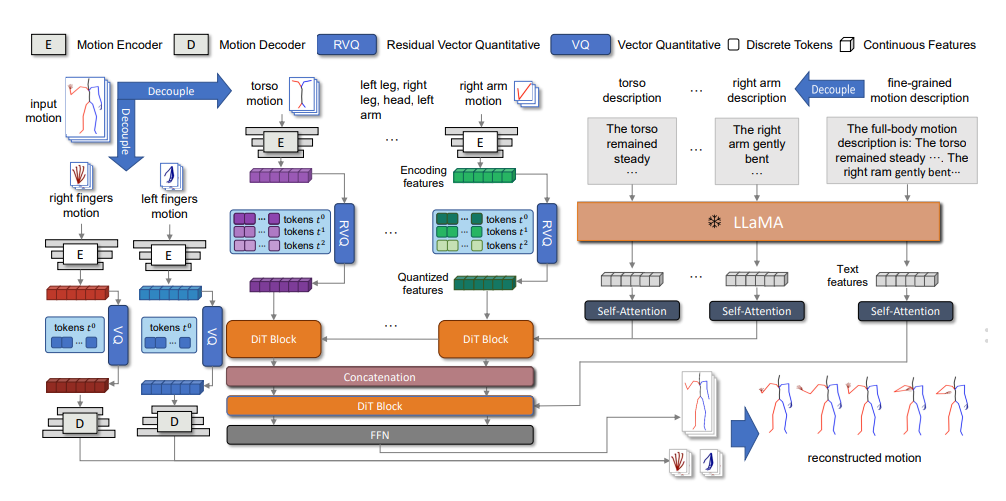
- R Li*, L Han*, S Shu*, Y Liu, Y Lin, Y Ma, J Guo†, Z Liu, X Li†. A Motion is Worth a Hybrid Sentence: Taming Language Model for Unified Motion Generation by Fine-grained Planning[C]. Proceedings of the 33rd ACM International Conference on Multimedia, 2025: 1404-1413. WOS:001656760500148. EI Accession number: 20255019680678
[Page]
|
|
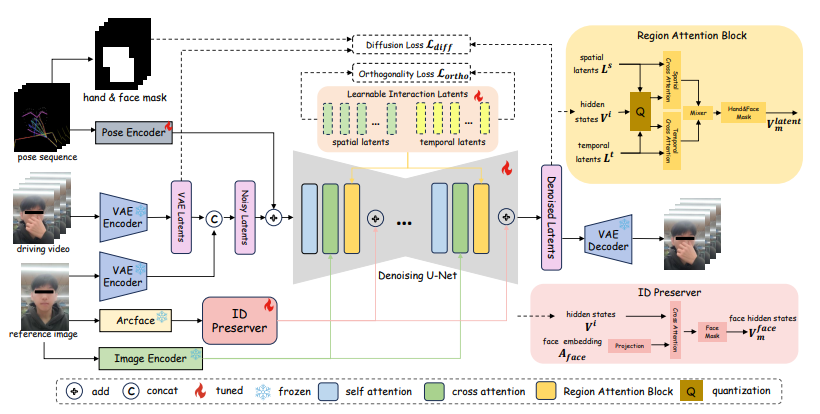
- Y Lin*, Y Hong*, Z Xu, X Li, C Xu, C Song, R Li, H Chen, J Lan, H Zhu†, W Wang, J Zhang, X Li†. Interanimate: Taming region-aware diffusion model for realistic human interaction animation[C]. Proceedings of the 33rd ACM International Conference on Multimedia, 2025: 1404-1413. WOS:001671135600291. EI Accession number: 20255019680793
[Page]
|
|
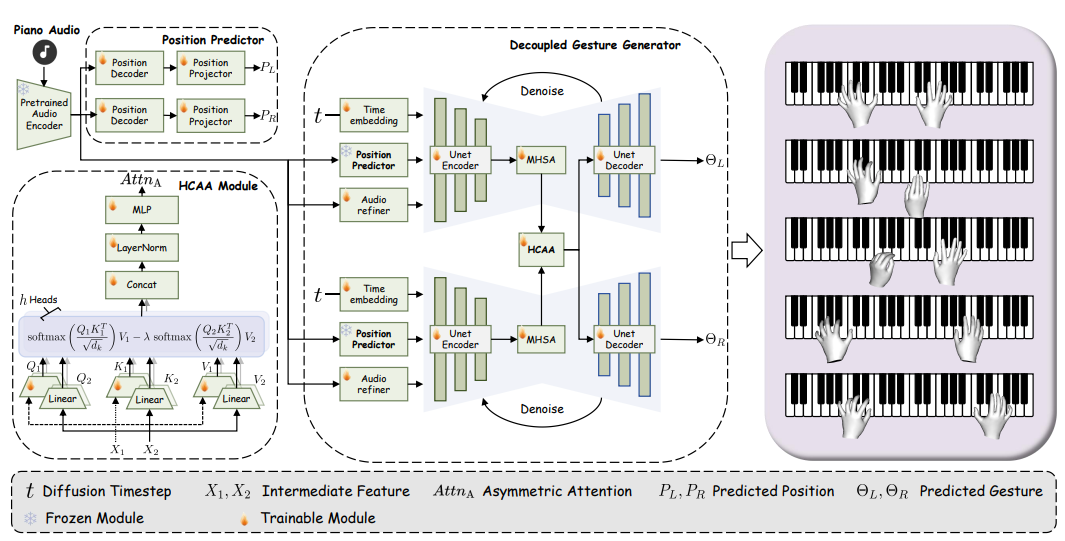
- Z Liu*, M Ou*, Z Xu*, J Huang, H Han, R Li, X Li†. Separate to Collaborate: Dual-Stream Diffusion Model for Coordinated Piano Hand Motion Synthesis[C]. Proceedings of the 33rd ACM International Conference on Multimedia, 2025: 1404-1413. WOS:001671135600233.EI Accession number: 20255019682058
[Page]
|

|
- J Wang, J Pu, Z Qi, J Guo, Y Ma, N Huang, Y Chen, X Li, Y Shan. Taming Rectified Flow for Inversion and Editing[C]. ICML, 2025. WOS:001693167600144. EI Accession number: 20254919637115
[Page]
|
|
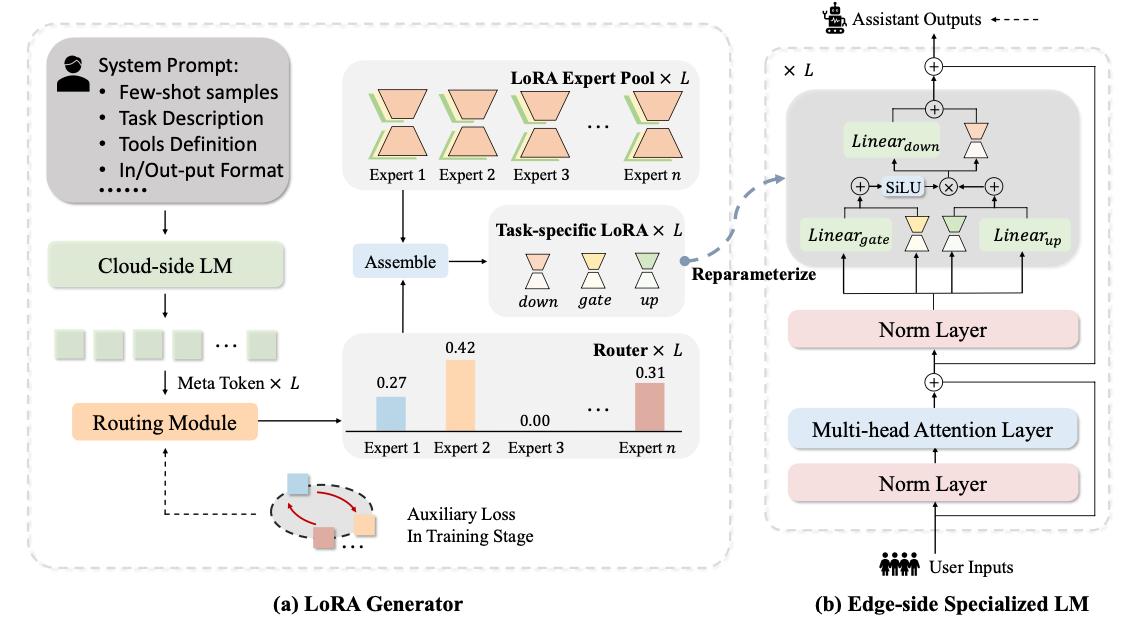
- Yicheng Xiao*, Lin Song*, Rui Yang, Cheng Cheng, Yixiao Ge, Xiu Li†, Ying Shan. LoRA-Gen: Specializing Large Language Model via Online LoRA Generation[C]. ICML, 2025. EI Accession number: 20254919647060
[Page]
|
|
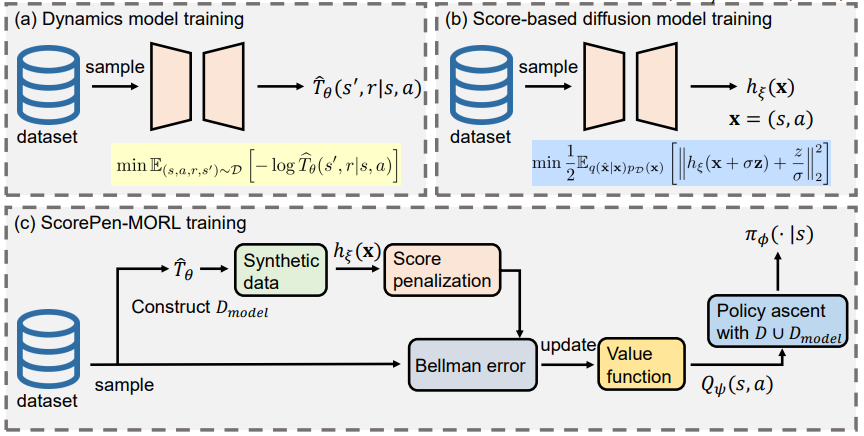
- Zeyuan Liu*, Zhirui Fang*, Jiafei Lyu, Xiu Li†. Leveraging Score-based Models for Generating Penalization in Model-based Offline Reinforcement Learning[C]. Proc of the 24th International Conference on Autonomous Agents and Multiagent Systems(AAMAS 2025), F, 2025. 1389-1398.
[Page]
|
|
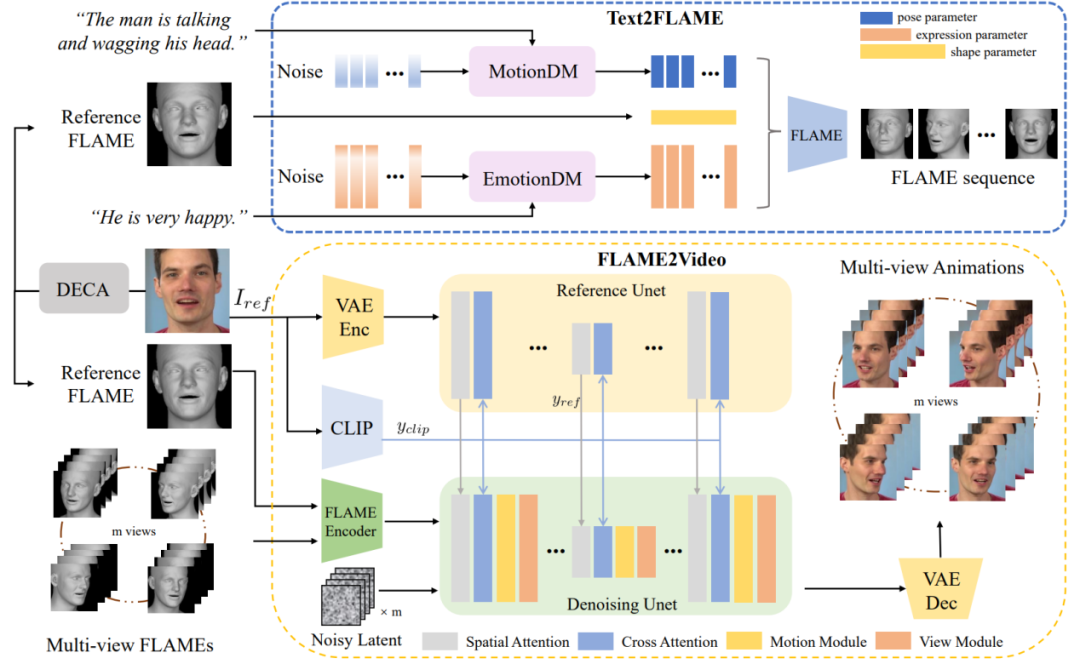
- Yukang Lin*, Hokit Fung*, Jianjin Xu, Zeping Ren, Adela S.M. Lau, Guosheng Yin†, Xiu Li†. MVPortrait: Text-Guided Motion and Emotion Control for Multi-view Vivid Portrait Animation[C]. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR-25), 2025. INSPEC:27165088. EI Accession number: 20253919240770.
[Page]
|
|
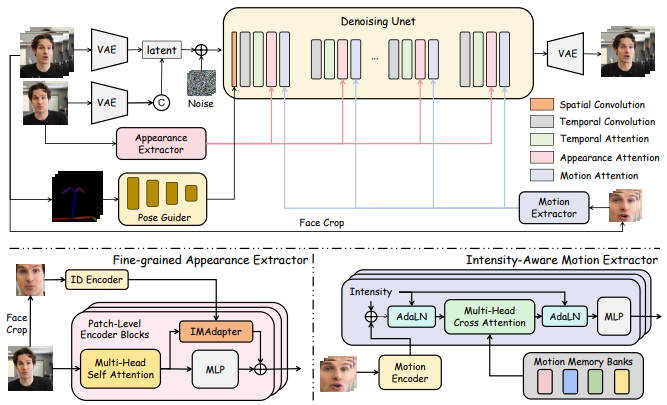
- Zunnan Xu, Zhentao Yu, Zixiang Zhou, Jun Zhou, Xiaoyu Jin, Fa-Ting Hong, Xiaozhong Ji, Junwei Zhu, Chengfei Cai, Shiyu Tang, Qin Lin, Xiu Li†, Qinglin Lu†. HunyuanPortrait: Implicit Condition Control for Enhanced Portrait Animation[C]. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR-25), 2025.
[Page] [Code] [Demo]
|
|
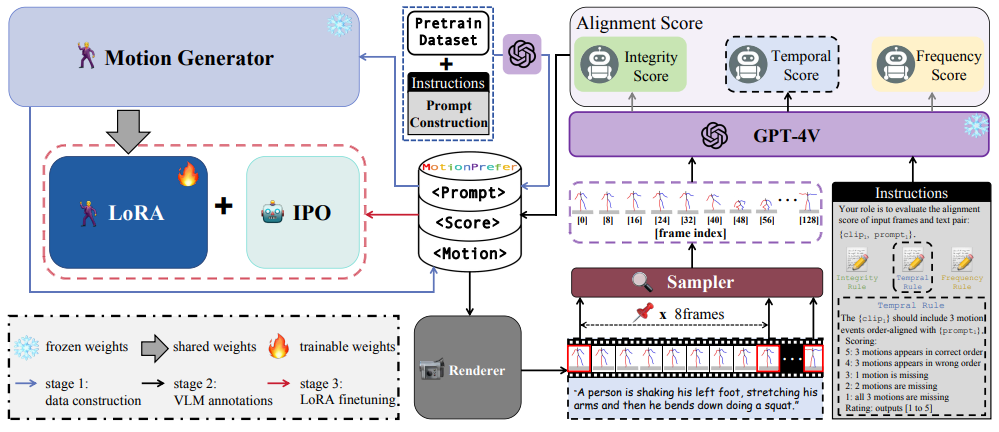
- Haonan Han*, Xiangzuo Wu*, Huan Liao*, Zunnan Xu, Zhongyuan Hu, Ronghui Li, Yachao Zhang†, Xiu Li†. AToM: Aligning Text-to-Motion Model at Event-Level with GPT-4Vision Reward[C]. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR-25), 2025. INSPEC:27325247. EI Accession number: 20240517811
[Page]
|
|
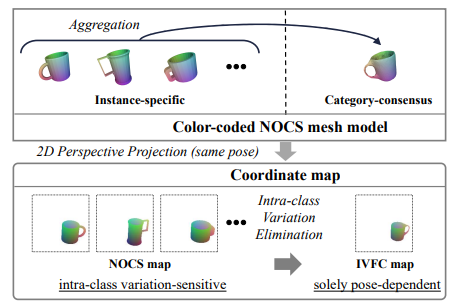
- Zinqin Huang, Gu Wang, Chenyangguang Zhang, Ruida Zhang, Xiu Li†, Xiangyang Ji. GIVEPose: Gradual Intra-class Variation Elimination for RGB-based Category-Level Object Pose Estimation[C]. In Proceedings of
the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR-25), 2025.
[Page]
|

|
- Chenyang Zhu*, Kai Li*,†, Yue Ma*, Longxiang Tang, Chengyu Fang, Chubin Chen, Qifeng Chen, Xiu
Li†. InstantSwap: Fast Customized Concept Swapping across Sharp Shape Differences[C]. In Proceedings of the International Conference
on Learning Representations (ICLR-25), 2025. EI Accession number: 20240527738
[Page] [Code]
|
|
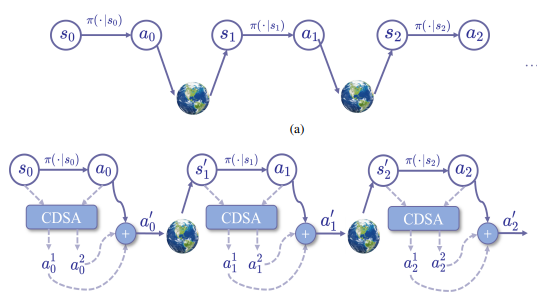
- Liu Zeyuan*, Yang Kai*, Lyu Jiafei, Li Xiu†. CDSA: Conservative Denoising Score-based Algorithm for Offline Reinforcement Learning[C]. In Proceedings of the 24rd International Conference on Autonomous Agents and Multiagent Systems, 2025. WOS:001532048100343. EI Accession number:20240284596
[Page]
|
|
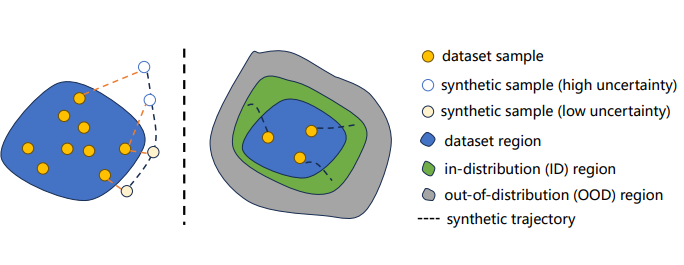
- Z Qiao, J Lyu, K Jiao, Q Liu, X Li†.
SUMO: Search-Based Uncertainty Estimation for Model-Based Offline Reinforcement Learning[C]. In The Thirty-Ninth AAAI Conference on Artificial Intelligence (AAAI), 2025. INSPEC:25525041. EI Accession number:20240372065
[Page]
|
|
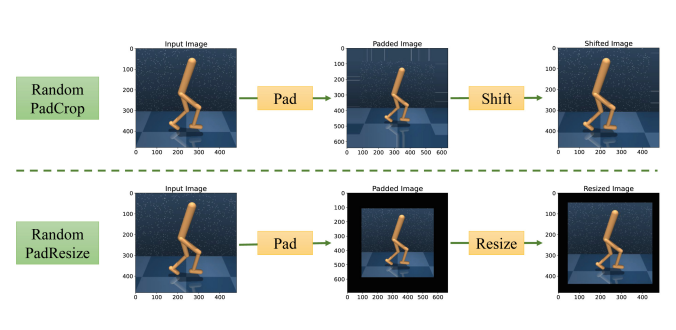
- Shengjie Sun, Jiafei Lyu, Lu Li, Jiazhe Guo, Mengbei Yan, Runze Liu, Xiu Li†. Enhancing Visual Generalization in Reinforcement Learning with Cycling Augmentation[C]. In International Conference on Artificial Neural Networks, Volume:15019, pp. 397-411. Cham: Springer Nature Switzerland, 2024. WOS:001331888400027. EI Accession number:20244017138467
[Page]
|
|
- Jian Tao*, Yangkun Chen*, Yang Zhang, Kai Yang, Xiu Li†. Multi-agent Exploration with Sub-state Entropy Estimation[C]. In 2024 International Joint Conference on Neural Networks (IJCNN), pp 1-9, IEEE, 2024. INSPEC:25619139. EI Accession number:20244017122431
[Page]
|
|
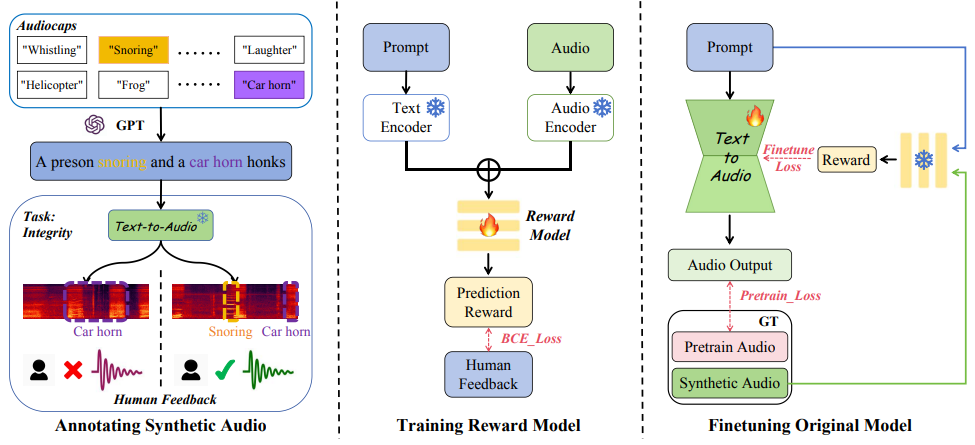
- Huan Liao*, Haonan Han*, Kai Yang, Tianjiao Du, Rui Yang, Zunnan Xu, Qinmei Xu, Jingquan Liu, Jiasheng Lu†, Xiu Li†. BATON: Aligning Text-to-Audio Model Using Human Preference Feedback[C]. In International Joint Conferences on Artificial Intelligence, 2024. EI Accession number:20243817075012
[Page]
|
|
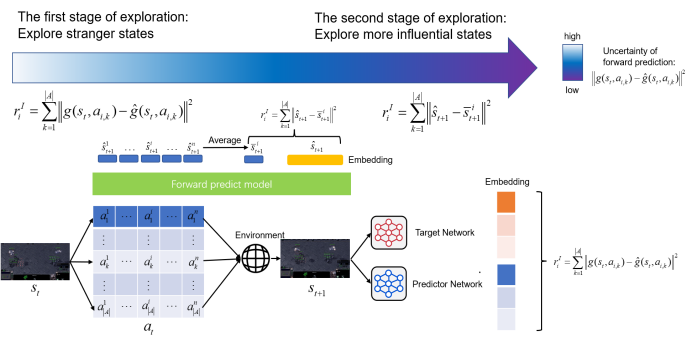
- Kai Yang*, Zhirui Fang*, Xiu Li†, Jian Tao. CMBE: Curiosity-driven Model-Based Exploration for Multi-Agent Reinforcement Learning in Sparse Reward Settings[C]. In 2024 International Joint Conference on Neural Networks (IJCNN), pp. 1-8. IEEE, 2024. INSPEC:25641595. EI Accession number:20244017121833
[Page]
|
|
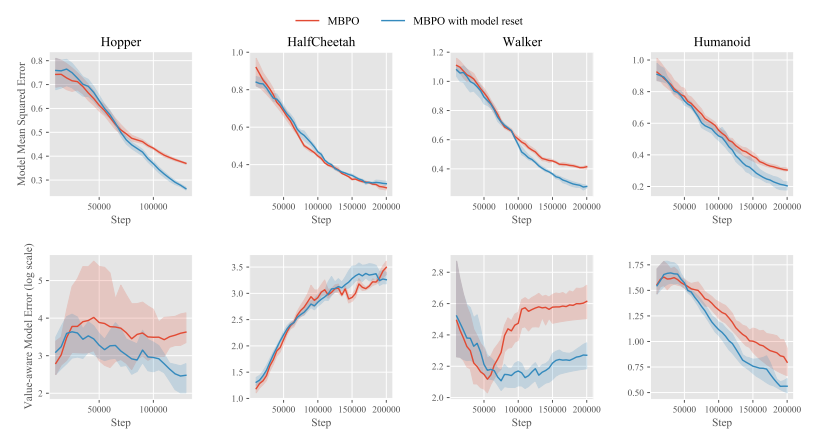
- Zhongjian Qiao, Jiafei Lyu, Xiu Li†. Mind the model, Not the agent: The primacy bias in Model-based RL[C]. In European Conference on Artificial Intelligence, 2024.
[Page]
|
|
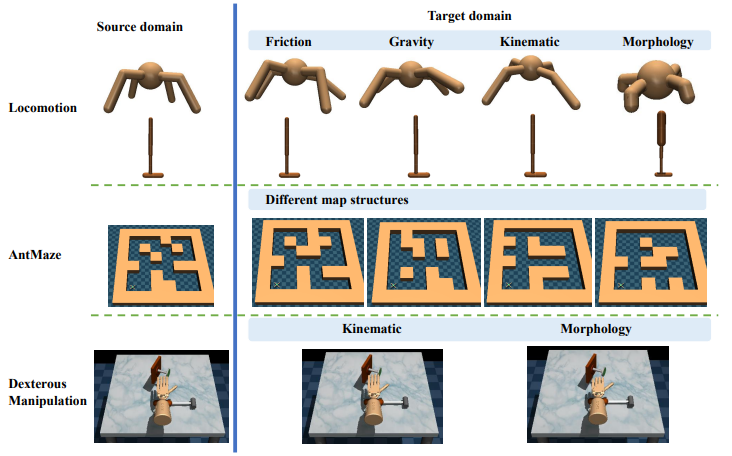
- Jiafei Lyu, Kang Xu, Jiacheng Xu, Mengbei Yan, Jingwen Yang, Zongzhang Zhang, Chenjia Bai†, Zongqing Lu, Xiu Li†. ODRL: A Benchmark for Off-Dynamics Reinforcement Learning[C]. In The Thirty-eight Conference on Neural Information Processing Systems Datasets and Benchmarks Track, 2024. EI Accession number:20240444723
[Page]
|
|
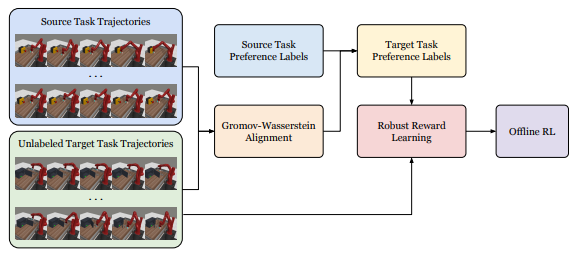
- Runze Liu, Yali Du†, Fengshuo Bai, Jiafei Lyu, Xiu Li†. PEARL: Zero-shot Cross-task Preference Alignment and Robust Reward Learning for Robotic Manipulation[C]. In International Conference on Machine Learning, 2024. EI Accession number:20243817050165
[Page]
|
|
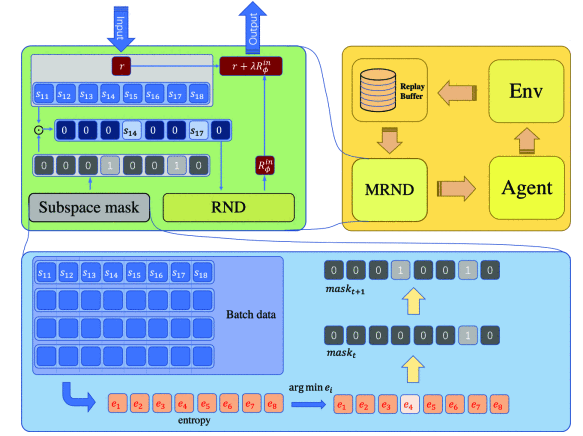
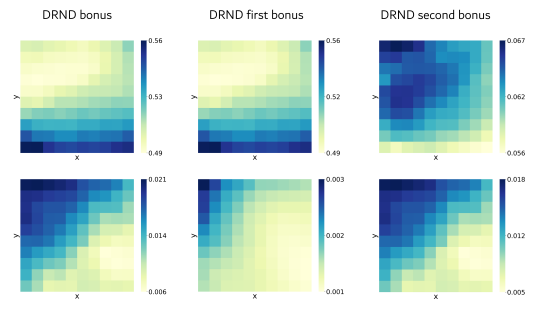
- Kai Yang*, Jian Tao*, Jiafei Lyu, Xiu Li†. Exploration and Anti-Exploration with Distributional Random Network Distillation[C]. In Forty-first International Conference on Machine Learning, 2024. INSPEC:24464620. EI Accession number:20243817052883
[Page]
|
|
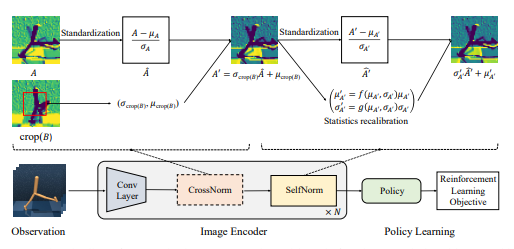
- Lu Li*, Jiafei Lyu*, Guozheng Ma, Zilin Wang, Zhenjie Yang, Xiu Li†, Zhiheng Li†. Normalization Enhances Generalization in Visual Reinforcement Learning[C]. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pp. 1137-1146. 2024. EI Accession number:20242516292862
[Page]
|
|
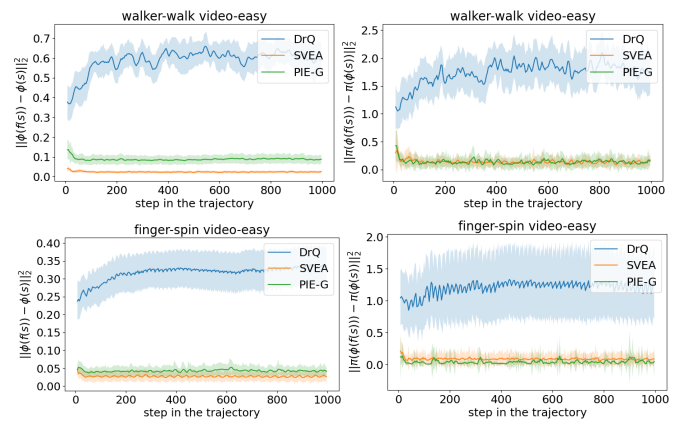
- Jiafei Lyu, Le Wan, Xiu Li†, Zongqing Lu†. Towards understanding how to reduce generalization gap in visual reinforcement learning[C]. In Proceedings of the 23rd International Conference on Autonomous Agents and Multiagent Systems, pp. 2369-2371. 2024. EI Accession number:20242516292554
[Page]
|
|
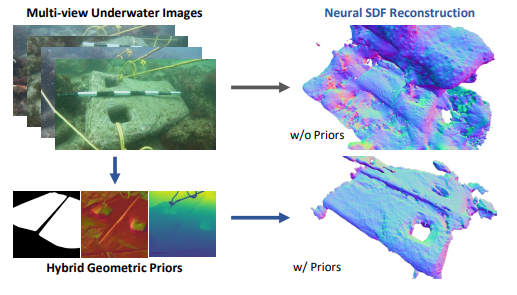
- Z Chen, J Tang, G Wang, S Li, X Li, X Ji, Xiu Li†. UW-SDF: Exploiting Hybrid Geometric Priors for Neural SDF Reconstruction from Underwater Multi-view Monocular Images[C]. The 2024 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS 24), 2024. INSPEC:25744503. EI Accession number:20240430290
[Page]
|
|
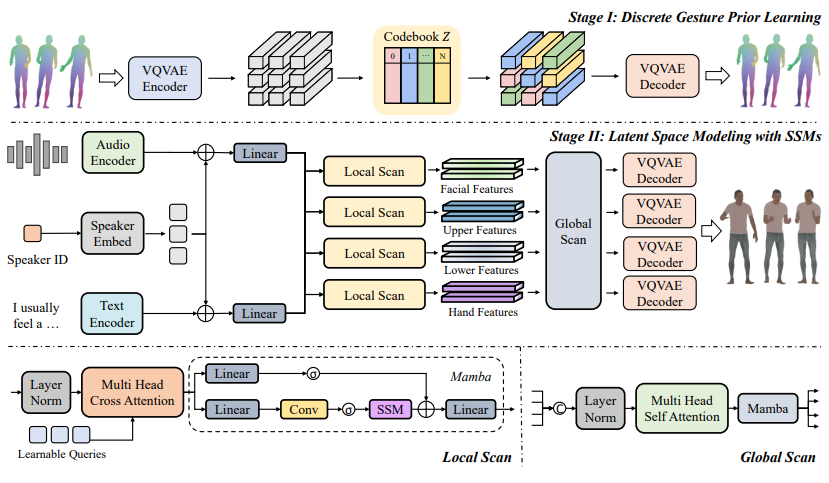
- Zunnan Xu, Yukang Lin, Haonan Han, Sicheng Yang, Ronghui Li, Yachao Zhang†, Xiu Li†. MambaTalk: Efficient Holistic Gesture Synthesis with Selective State Space Models[C]. Advances in Neural Information Processing
Systems (NeurIPS-24), 2024. INSPEC:24837391. EI Accession number:20240124955
[Page]
|
|
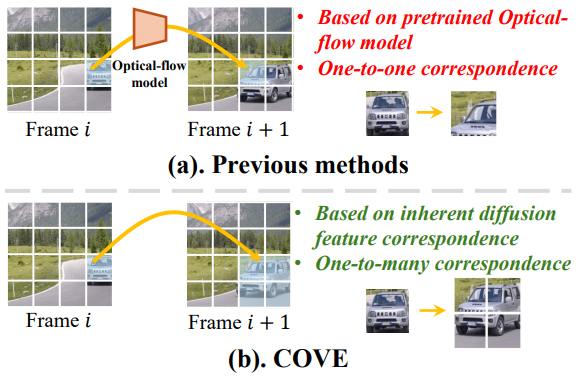
- Jiangshan Wang*, Yue Ma*, Jiayi Guo*, Yicheng Xiao, Gao Huang†, Xiu Li†. COVE: Unleashing the Diffusion Feature Correspondence for Consistent Video Editing[C]. Advances in Neural Information Processing
Systems (NeurIPS-24), 2024. INSPEC:25205832. EI Accession number:20240265709
[Page] [Code]
|
|
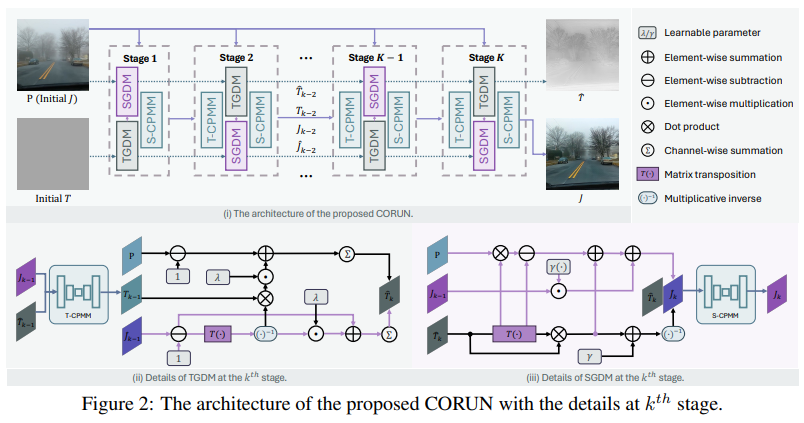
- Chengyu Fang*, Fengyang Xiao, Chunming He*,†, Yulun Zhang†, Longxiang Tang, Yuelin Zhang, Kai Li, Xiu Li†. Real-world Image Dehazing with Coherence-based Label Generator and Cooperative Unfolding Network[C]. Advances in Neural Information Processing
Systems (NeurIPS-24), 2024. INSPEC:25204966. EI Accession number:20240261457
[Page] [Code]
|
|
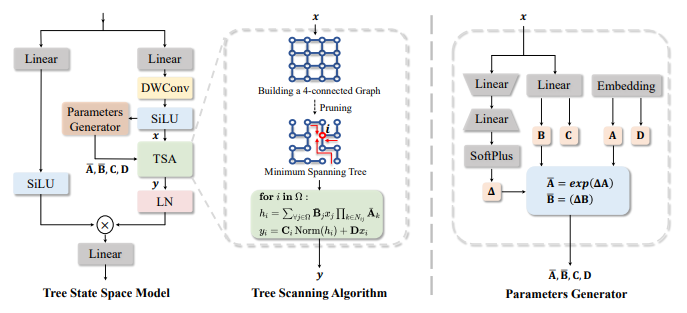
- Yicheng Xiao, Lin Song, Shaoli Huang, Jiangshan Wang, Siyu Song, Yixiao Ge, Xiu Li, Ying Shan. MambaTree: Tree Topology is All You Need in State Space Model[C]. The Thirty-eighth Annual Conference on Neural Information Processing Systems(NeurIPS-24), 2024.
[Page] [Code]
|
|
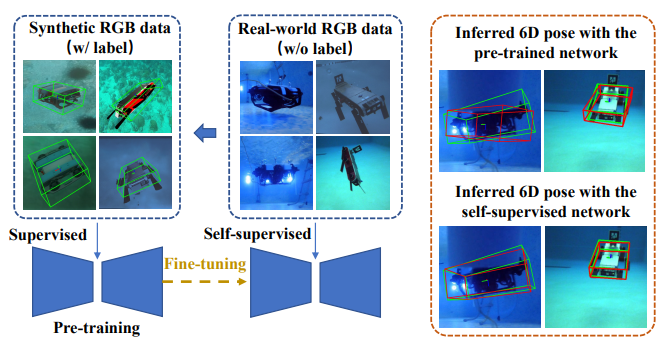
- Jingyi Tang*, Gu Wang*, Zeyu Chen, Shengquan Li, Xiu Li†, Xiangyang Ji. FAFA: Frequency-Aware Flow-Aided Self-Supervision for Underwater Object Pose Estimation[C]. European
Conference on Computer Vision (ECCV-24), 2024. INSPEC:25938615. EI Accession number:20240427089
[Page]
|

|
- Zeping Ren,Shaoli Huang†, Xiu Li†. Realistic Human Motion Generation with Cross-Diffusion Models[C]. European
Conference on Computer Vision (ECCV-24), 2024. WOS:001378254400020. EI Accession number: 20230458804
[Page] [Code] [Data]
|

|
- Yifan Pu*, Zhuofan Xia*, Jiayi Guo, Dongchen Han, Qixiu Li, Duo Li, Yuhui Yuan, Ji Li, Yizeng Han, Shiji Song, Gao Huang†, Xiu Li†. Efficient Diffusion Transformer with Step-wise Dynamic Attention Mediators[C]. European
Conference on Computer Vision (ECCV-24), 2024. INSPEC:25484352. EI Accession number: 20240346913
[Page] [Code]
|
|
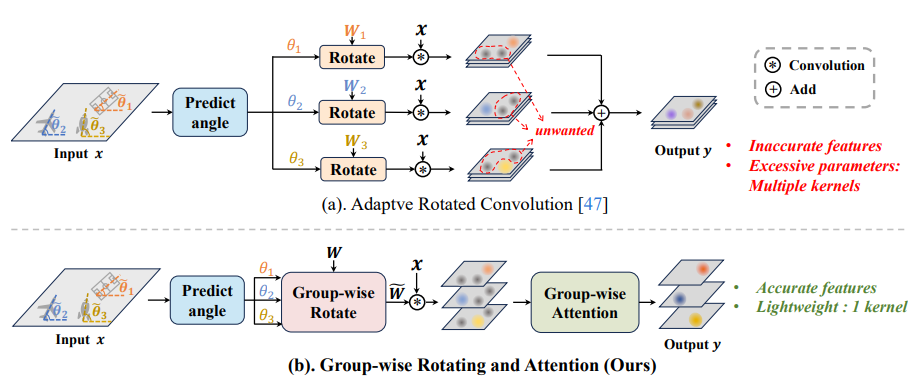
- Jiangshan Wang*, Yifan Pu*, Yizeng Han, Jiayi Guo, Yiru Wang, Xiu Li†, Gao Huang†. GRA: Detecting Oriented Objects through Group-wise Rotating and Attention[C]. European
Conference on Computer Vision (ECCV-24), 2024. EI Accession number: 20240127662
[Page]
|
|
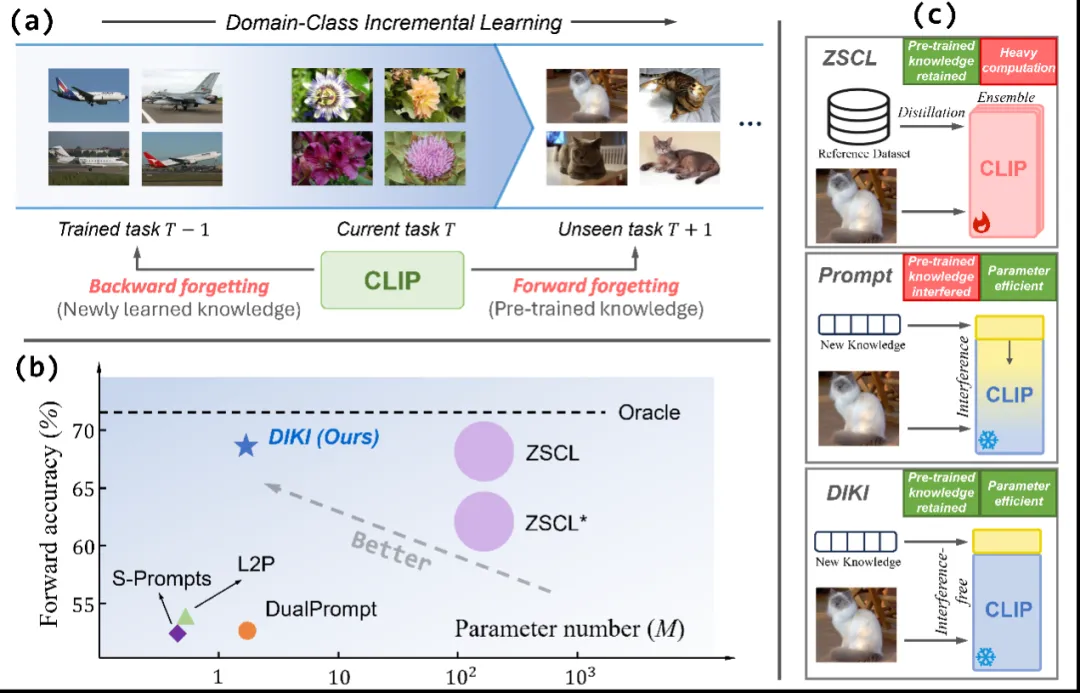
- Longxiang Tang, Zhuotao Tian, Kai Li, Chunming He, Hantao Zhou,
Hengshuang Zhao, Xiu Li†, Jiaya Jia. Mind the
Interference: Retaining Pre-trained Knowledge in Parameter Efficient
Continual Learning of Vision-Language Models[C]. European
Conference on Computer Vision (ECCV-24), 2024. EI Accession number:20240305908
[Page] [Code]
[Data]
|
|
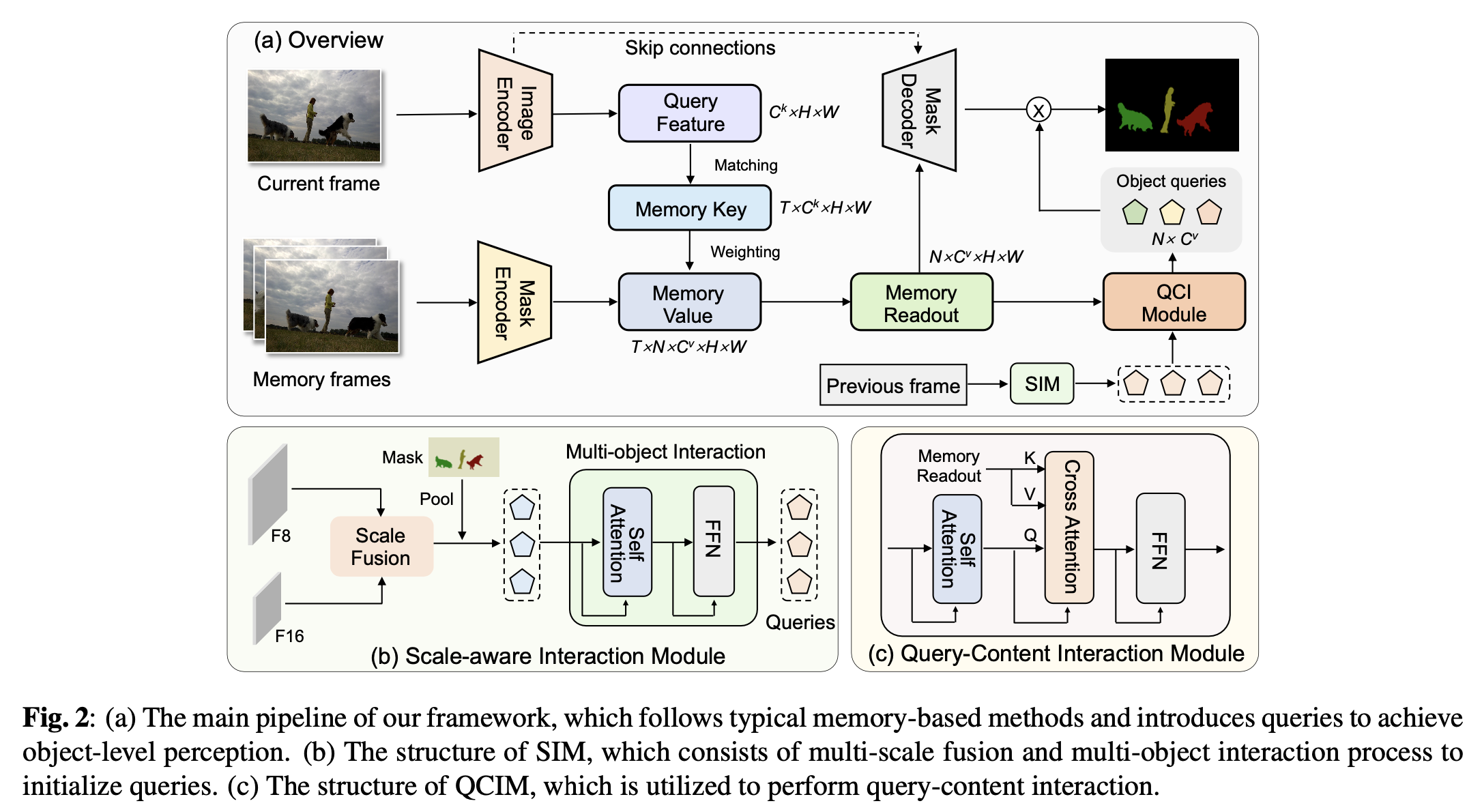
- Hantao Zhou, Runze Hu†, Xiu Li†. Video
Object Segmentation with Dynamic Query Modulation[C]. In
Proceedings of the 2024 IEEE
International Conference on Multimedia and Expo
(ICME-24). IEEE, 2024. INSPEC:24843118. EI Accession number: 20240128343
[Page] [Code]
|
|
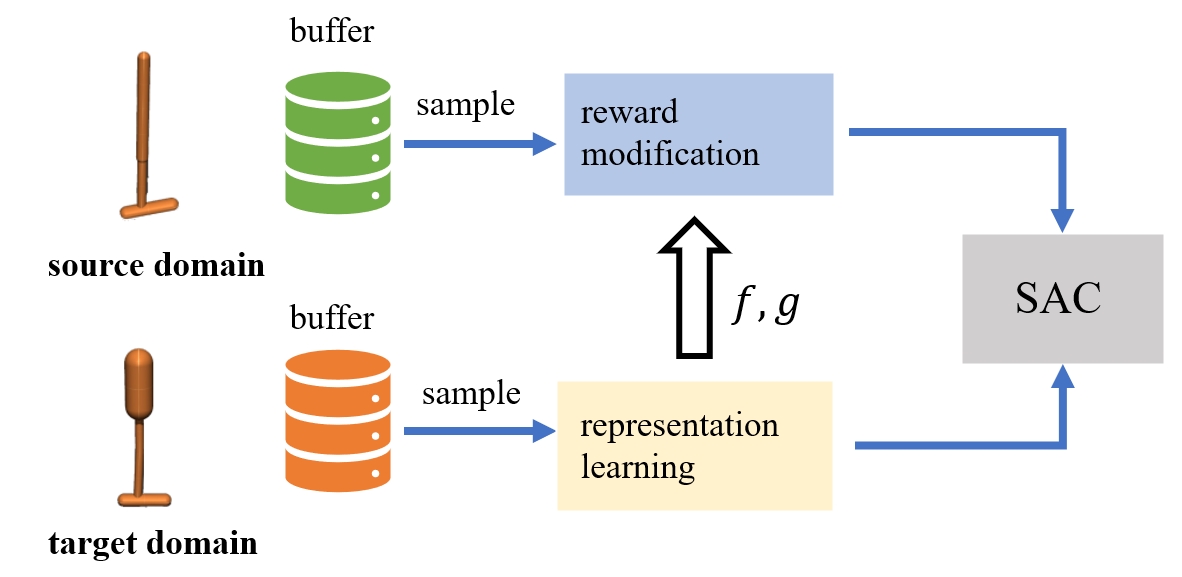
- Jiafei Lyu, Chenjia Bai, Jingwen Yang, Zongqing Lu, Xiu Li†. Cross-Domain Policy Adaptation by Capturing
Representation Mismatch[C]. ICML, 2024. INSPEC:25316967. EI Accession number: 20240229502
[Page] [Code]
|

|
- Ronghui Li, YuXiang Zhang, Yachao Zhang, Hongwen Zhang, Jie Guo, Yan
Zhang, Yebin Liu, Xiu Li†. Lodge: A
Coarse to Fine Diffusion Network for Long Dance Generation Guided by
the Characteristic Dance Primitives[C]. In Proceedings of
the IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR-24), 2024. INSPEC:24842557. EI Accession number: 20240129491
[Page] [Code] [Data]
|
|
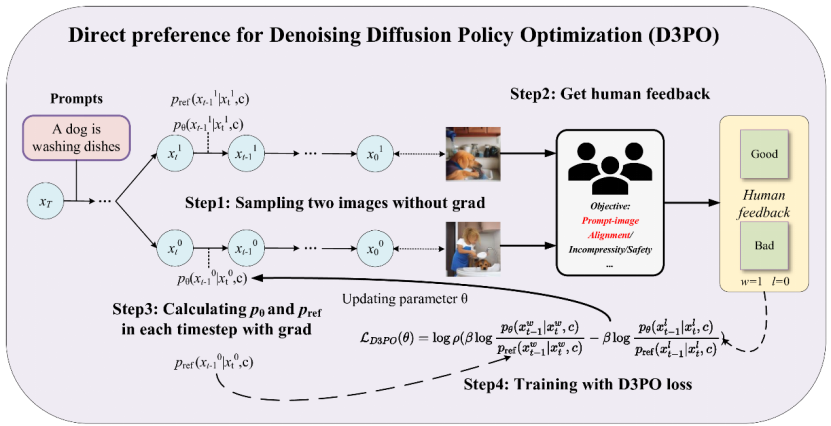
- Kai Yang*, Jian Tao*, Jiafei Lyu†, Chunjiang Ge, Qimai Li, Jiaxin Chen,
Weihan Shen, Xiaolong Zhu, Xiu Li†. Using
Human Feedback to Fine-tune Diffusion Models without Any Reward
Model[C]. In Proceedings of the IEEE/CVF Conference on
Computer Vision and Pattern Recognition (CVPR-24), 2024. INSPEC:24150778. EI Accession number: 20230432990
[Page] [Code] [Data]
|
|
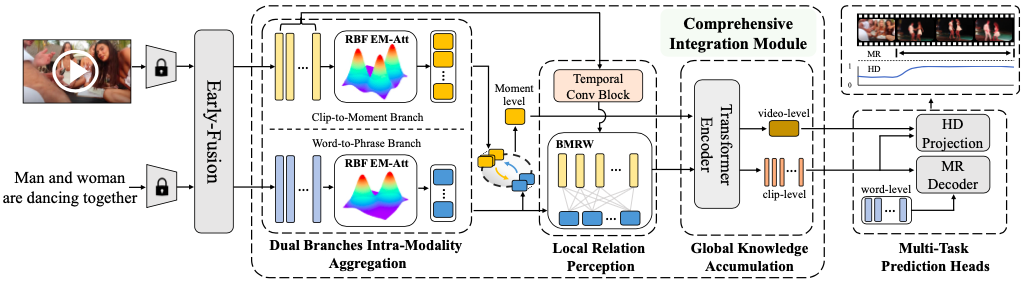
- Yicheng Xiao*, Zhuoyan Luo*, Yong Liu, Yue Ma, Hengwei Bian, Yatai Ji,
Yujiu Yang†, Xiu Li†. Bridging the Gap: A Unified Video Comprehension
Framework for Moment Retrieval and Highlight Detection[C].
In Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR-24), 2024. INSPEC:24221468. EI Accession number: 20230428618
[Page] [Code] [Data]
|
|
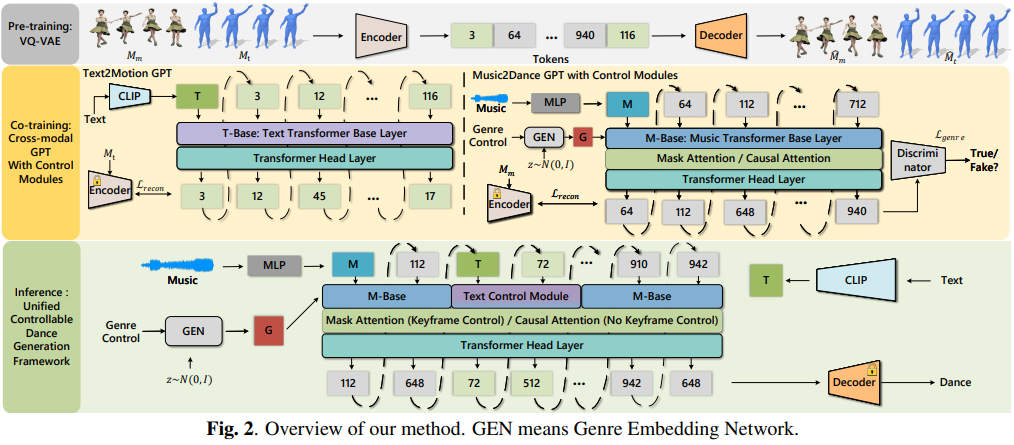
- Ronghui Li*, Yuqin Dai*, Yachao Zhang†, Jun Li, Jian Yang, Jie Guo, Xiu
Li†. Exploring Multi-Modal Control in Music-Driven
Dance Generation[C]. In Proceedings of the International
Conference on Acoustics, Speech and Signal Processing
(ICASSP-24). INSPEC:25425862. EI Accession number: 20240036939
[Page]
|
|
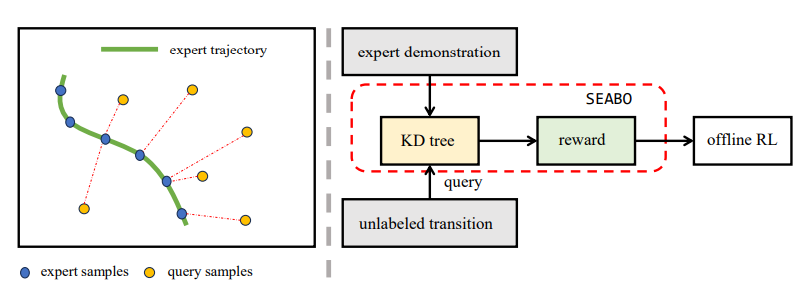
- Jiafei Lyu, Xiaoteng Ma, Le Wan, Runze Liu, Xiu Li†, Lu Zongqing†. SEABO: A
Simple Search-Based Method for Offline Imitation Learning[C].
In Proceedings of the International Conference on Learning
Representations (ICLR-24), 2024. INSPEC:24608646. EI Accession number: 20240072425
[Page] [Code]
|
|
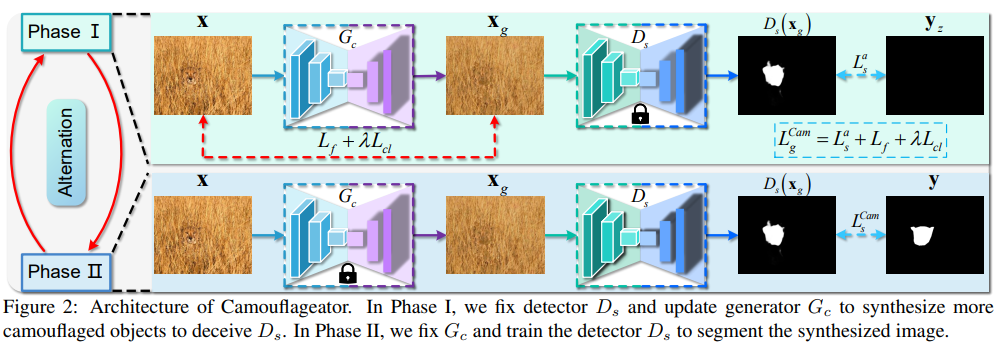
- Chunming He, Kai Li†, Yachao Zhang, Yulun Zhang, Zhenhua Guo, Xiu
Li†, et al. Strategic Preys Make Acute Predators: Enhancing
Camouflaged Object Detectors by Generating Camouflaged
Objects[C]. In Proceedings of the International Conference
on Learning Representations (ICLR-24), 2024. EI Accession number: 20230298105
[Page] [Code]
|
|
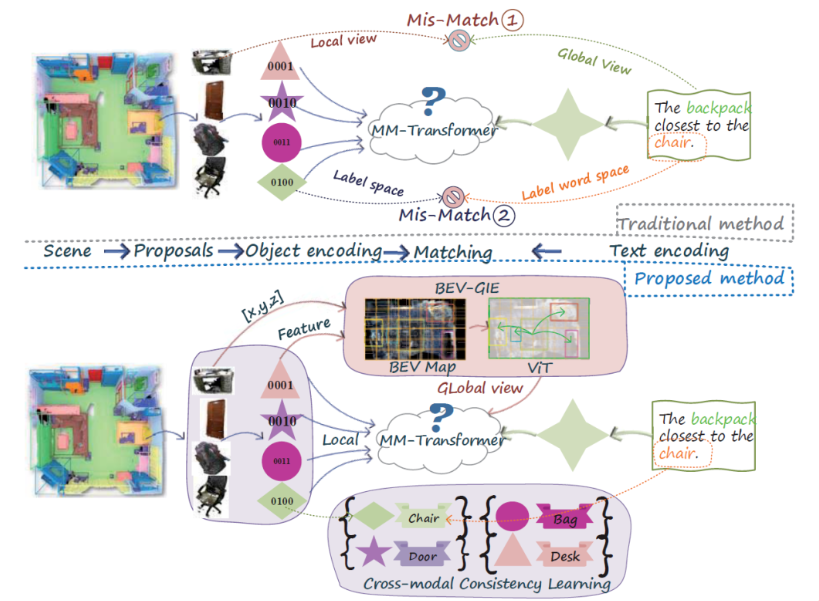
- Yachao Zhang, Runze Hu, Ronghui Li, Yanyun Qu, Yuan Xie, Xiu Li†.
Cross-Modal Match for Language Conditioned 3D
Object Grounding[C]. In Proceedings of the Association for
the Advance of Artificial Intelligence (AAAI-24), 2024. WOS:001239937300096. EI Accession number: 20241515870430
[Page]
|

|
- Yue Ma*, Yingqing He*, Xiaodong Cun, Xintao Wang, Siran Chen, Ying Shan,
Xiu Li†, Chen Qifeng†. Follow Your Pose: Pose-Guided Text-to-Video
Generation using Pose-Free Videos[C]. In Proceedings of
the Association for the Advance of Artificial Intelligence
(AAAI-24), 2024. INSPEC:23392848. EI Accession number: 20241515870526
[Page] [Code] [Demo]
|

|
- Zunnan Xu, Yachao Zhang, Sicheng Yang, Ronghui Li, Xiu Li†. Chain of
Generation: Multi-Modal Gesture Synthesis via Cascaded Conditional
Control[C]. In Proceedings of the Association for the
Advance of Artificial Intelligence (AAAI-24), 2024. WOS:001239936300144. EI Accession number: 20241515867359
[Page] [Data]
|

|
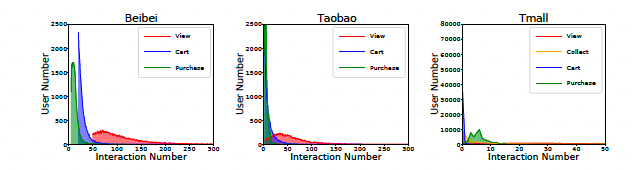
- C Meng*, H Zhang*, W Guo, H Guo, H Liu, Y Zhang, H Zheng, R Tang†, X
Li†, et al. Hierarchical Projection Enhanced Multi-Behavior
Recommendation[C]. In Proceedings of the 29th ACM SIGKDD
Conference on Knowledge Discovery and Data Mining
(SIGKDD-23), 2023: 4649-4660. INSPEC:24293931. EI Accession number: 20233814747821
[Page] [Code] [Data]
|
|
- Chang Meng*, Chenhao Zhai*, Yu Yang, Hengyu Zhang, Xiu Li†. Parallel
Knowledge Enhancement based Framework for Multi-behavior
Recommendation[C]. In Proceedings of the ACM International
Conference on Information & Knowledge Management
(CIKM-23), 2023: 4649-4660. WOS:001161549501087. EI Accession number: 20230286107
[Page] [Code] [Data]
|

|
- C He, K Li†, Y Zhang, L Tang, Y Zhang, X Li†. Camouflaged object detection with feature
decomposition and edge reconstruction[C]. In Proceedings
of the IEEE/CVF Conference on Computer Vision and Pattern
Recognition (CVPR-23), 2023: 22046-22055. WOS:001062531306037. EI Accession number: 20234114867985
[Page] [Code] [Data]
|
|
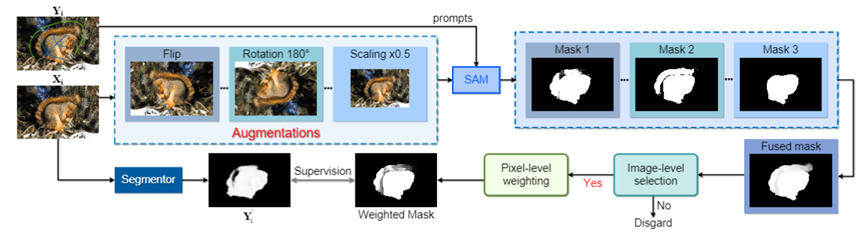
- C He*, K Li*, Y Zhang, L Tang, Y Zhang, Z Guo, X Li†. Weakly-Supervised Concealed Object Segmentation
with SAM-based Pseudo Labeling and Multi-scale Feature
Grouping[C]. Advances in Neural Information Processing
Systems (NeurIPS-23), 2023. WOS:001230083404048. EI Accession number: 20230197582
[Page] [Code] [Data]
|

|
- C He, K Li†, G Xu, Y Zhang, R Hu, Z Guo, X Li†. Degradation-Resistant Unfolding Network for
Heterogeneous Image Fusion[C]. In Proceedings of the
IEEE/CVF International Conference on Computer Vision
(ICCV-23), 2023: 12611-12621. WOS:001169499005005. EI Accession number: 20240915635855
[Page] [Code] [Data] [Demo]
|
|
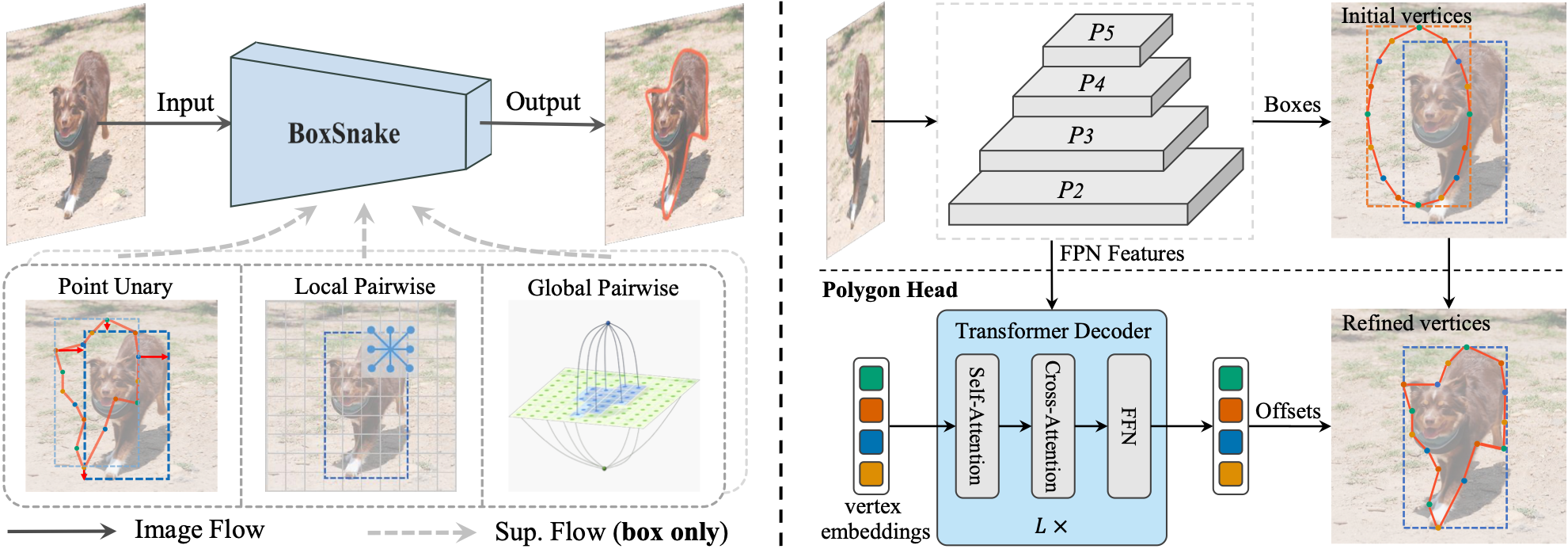
- Rui Yang*, Lin Song*,†, Yixiao Ge, Xiu Li†. BoxSnake: Polygonal Instance Segmentation with
Box Supervision[C]. In Proceedings of the IEEE/CVF
International Conference on Computer Vision (ICCV-23),
2023: 2303.11630. WOS:001159644301002. EI Accession number: 20230100468
[Page] [Code] [Data]
|

|
- Yicheng Xiao*, Yue Ma*, Shuyan Li, Hantao Zhou, Ran Liao, Xiu Li†.
SemanticAC: Semantics-Assisted Framework for
Audio Classification[C]. In Proceedings of the
International Conference on Acoustics, Speech and Signal
Processing (ICASSP-23). INSPEC:23981758. EI Accession number: 20235215285454
[Page] [Data]
|

|
- L Tang, K Li, C He, Y Zhang, X Li†. Consistency Regularization for Generalizable
Source-free Domain Adaptation[C]. In Proceedings of the
IEEE/CVF International Conference on Computer Vision
(ICCV-23), 2023: 4323-4333. INSPEC:24314627. EI Accession number: 20230292197
[Page] [Code] [Data]
|
|
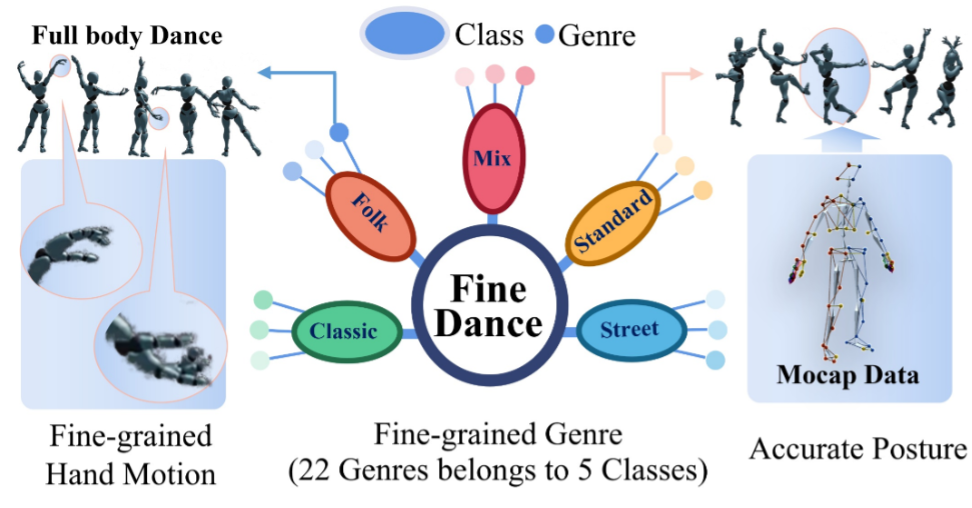
- Ronghui Li*, Junfan Zhao*, Yachao Zhang, Mingyang Su, Zeping Ren, Han
Zhang, Yansong Tang, Xiu Li†. FineDance: A Fine-grained Choreography Dataset
for 3D Full Body Dance Generation[C]. In Proceedings of
the IEEE/CVF International Conference on Computer Vision
(ICCV-23), 2023. WOS:001169499002060. EI Accession number: 20240915635311
[Page] [Code] [Data] [Demo]
|
|
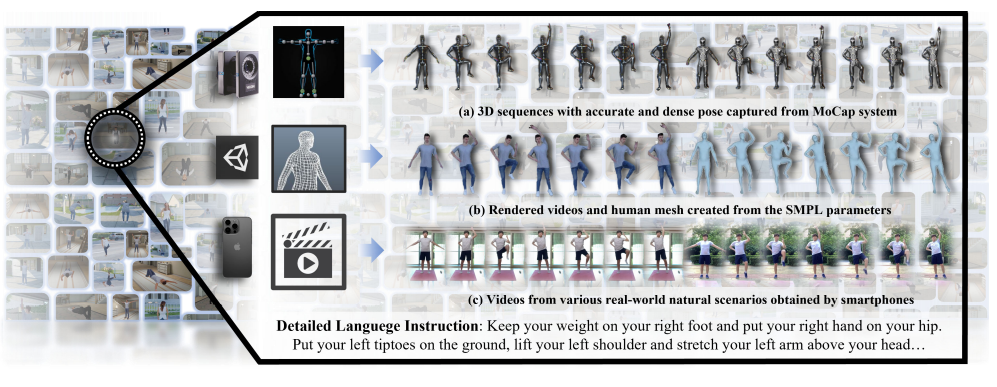
- Y Tang*, J Liu*, A Liu*, B Yang, W Dai, Y Rao, J Lu, J Zhou, X Li†.
Flag3d: A 3d fitness activity dataset
with language instruction[C]. In Proceedings of the
IEEE/CVF Conference on Computer Vision and Pattern Recognition
(CVPR-23), 2023: 22106-22117. WOS:001062531306042. EI Accession number: 20234114867188
[Page] [Demo]
|
|
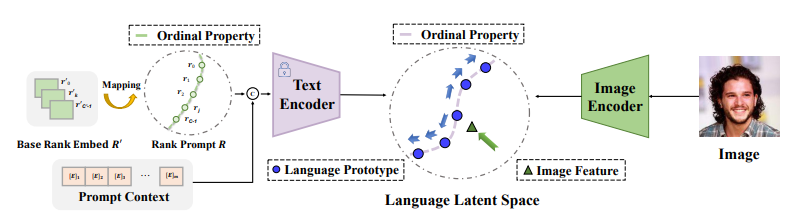
- W Li, X Huang, Z Zhu, Y Tang, X Li, J Zhou, J Lu. Ordinalclip: Learning rank prompts for
language-guided ordinal regression[C]. Advances in Neural
Information Processing Systems (NeurIPS-22), 2022, 35:
35313-35325. WOS:001213811606044. EI Accession number: 20232614295653
[Page] [Code] [Data]
|
|
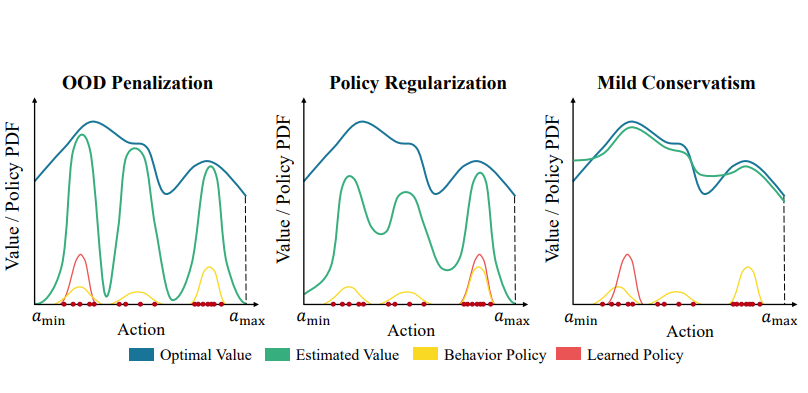
- J Lyu*, X Ma*, X Li†, Z Lu†. Mildly conservative Q-learning for offline
reinforcement learning[C]. Advances in Neural Information
Processing Systems (NeurIPS-22), 2022, 35: 1711-1724. WOS:001202259105016. EI Accession number: 20220175714
[Page] [Code]
|
|
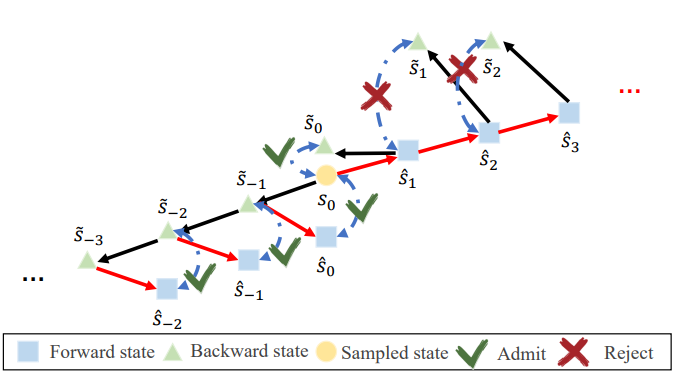
- J Lyu, X Li†, Z Lu†. Double Check Your State Before Trusting It:
Confidence-Aware Bidirectional Offline Model-Based
Imagination[C]. Advances in Neural Information Processing
Systems (NeurIPS-22), 2022, 35: 38218-38231. WOS:001213811602048. EI Accession number: 20220213717
[Page] [Code]
|
|
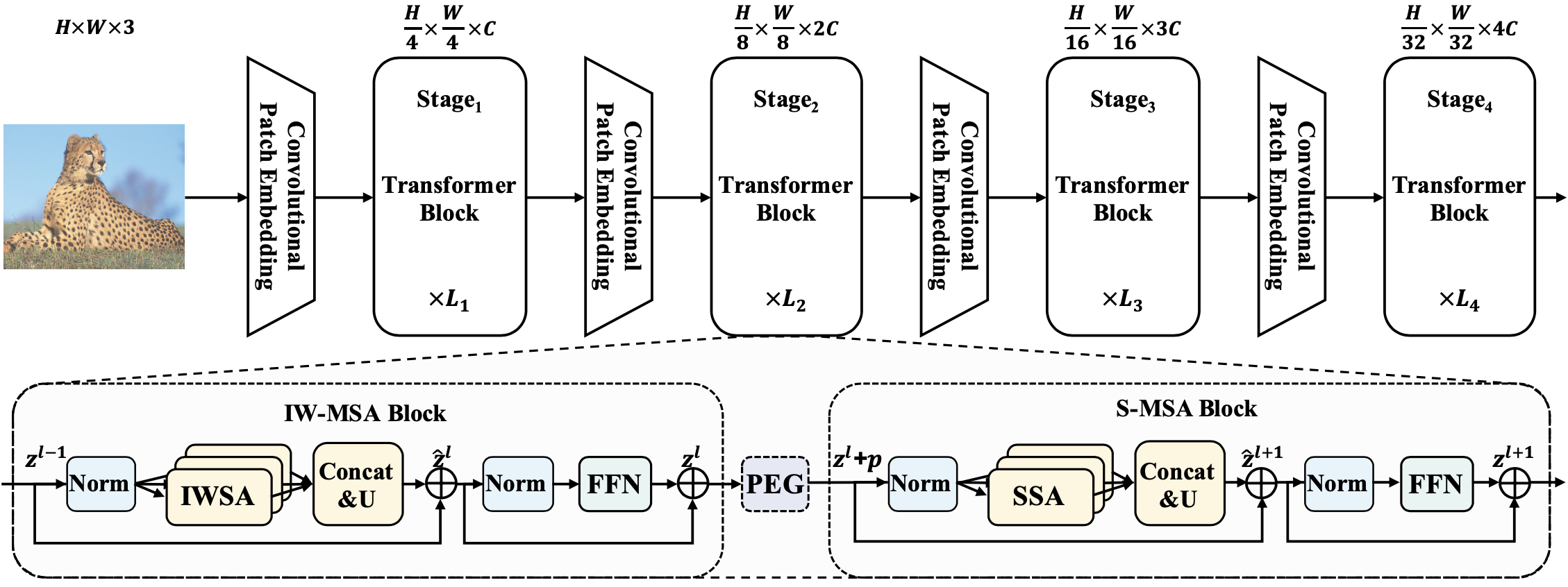
- R Yang*, H Ma*, J Wu†, Y Tang, X Xiao, M Zheng, X Li†. Scalablevit: Rethinking the context-oriented
generalization of vision transformer[C]. European
Conference on Computer Vision (ECCV-22), 2022: 480-496. WOS:000904279900028. EI Accession number: 20224813183989
[Page] [Code]
|

|
- Yukang Lin*, Haonan Han*, Chaoqun Gong, Zunnan Xu, Yachao Zhang, Xiu Li†. Consistent123: One Image to Highly Consistent 3D Asset Using Case-Aware Diffusion Priors[C]. In Proceedings of the 32nd ACM
International Conference on Multimedia (ACM MM-24), 2024:6715-6724. WOS:001556095000075. EI Accession number:20244817417843
[Page]
|
|
- Z Chen, C Wang, H Zhao, B Yuan, X Li. D2Animator: Dual Distillation of StyleGAN For
High-Resolution Face Animation[C]. In Proceedings of the
30th ACM International Conference on Multimedia (ACM
MM-22), 2022: 1769-1778. WOS:001150372701090. EI Accession number: 20231413827321
[Page]
|
|
- Y Ma, Y Wang, Y Wu, Z Lyu, S Chen, X Li, Y Qiao. Visual knowledge graph for human action
reasoning in videos[C]. In Proceedings of the 30th ACM
International Conference on Multimedia (ACM MM-22),
2022: 4132-4141. WOS:001150372704020. EI Accession number: 20231313815249
[Page] [Code]
|

|
- H Zhang*, E Yuan*, W Guo, Z He, J Qin, H Guo, B Chen, X Li†, R Tang†.
Disentangling Past-Future Modeling in Sequential
Recommendation via Dual Networks[C]. In Proceedings of the
31st ACM International Conference on Information & Knowledge
Management (CIKM-22), 2022: 2549-2558. WOS:001074639602051. EI Accession number: 20224413038356
[Page] [Code] [Data]
|
|
- R Yang, Y Lu, W Li, H Sun, M Fang, Y Du, X Li, et al. Rethinking Goal-conditioned Supervised Learning
and Its Connection to Offline RL[C]. In Proceedings of the
International Conference on Learning Representations
(ICLR-22), 2022. EI Accession number: 20220023978
[Page]
|
|
- Jiafei Lyu*, Xiaoteng Ma*, Jiangpeng Yan, Xiu Li†. Efficient continuous control with double actors
and regularized critics[C]. In Proceedings of the AAAI
Conference on Artificial Intelligence (AAAI-22), 2022. WOS:000893639100067. EI Accession number: 20230713576345
[Page] [Code]
|
|
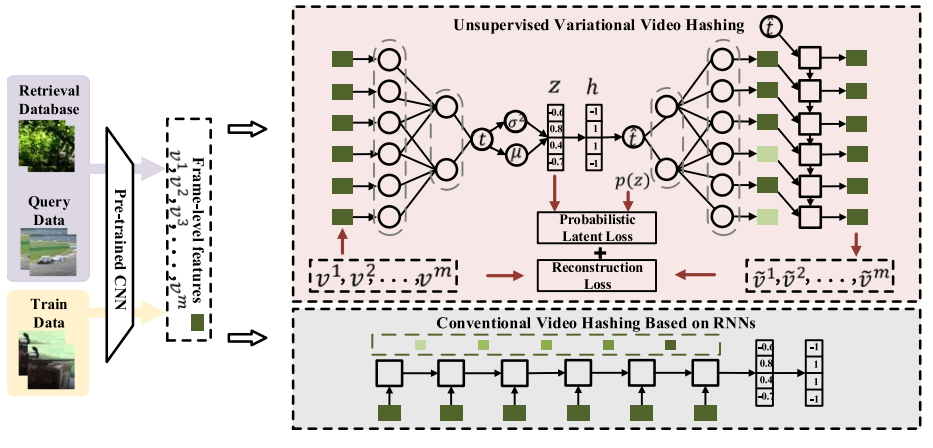
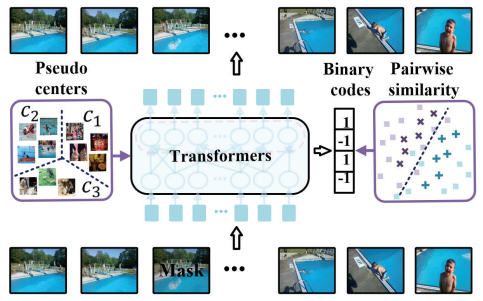
- Shuyan Li, Xiu Li, Jiwen Lu, Jie Zhou. Self-supervised video hashing via bidirectional
transformers[C]. In Proceedings of the IEEE/CVF
Conference on Computer Vision and Pattern Recognition
(CVPR-21) 2021:13549-13558. WOS:000742075003074. EI Accession number: 20220411509914
[Page] [Code] [Data]
|
|
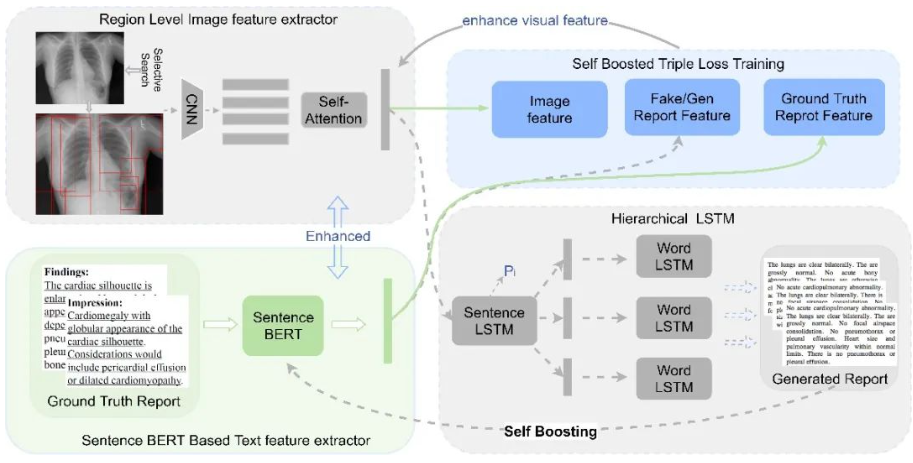
- Wang Z, Zhou L, Wang L, Li X†. A
Self-boosting Framework for Automated Radiographic Report
Generation[C]. In Proceedings of the IEEE/CVF Conference
on Computer Vision and Pattern Recognition (CVPR-21),
2021, 2433-2442. WOS:000739917302061. EI Accession number: 20220411509427
[Page]
|
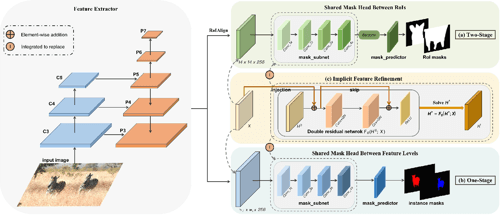
|
- Lufan Ma*, Tiancai Wang*, Bin Dong, Jiangpeng Yan, Xiu Li†, Xiangyu Zhang. Implicit Feature Refinement for Instance
Segmentation[C]. In Proceedings of the 29th ACM
International Conference on Multimedia (ACMMM-21) 2021,
3088-3096. WOS:001147786903017. EI Accession number: 20214711200146
[Page]
|
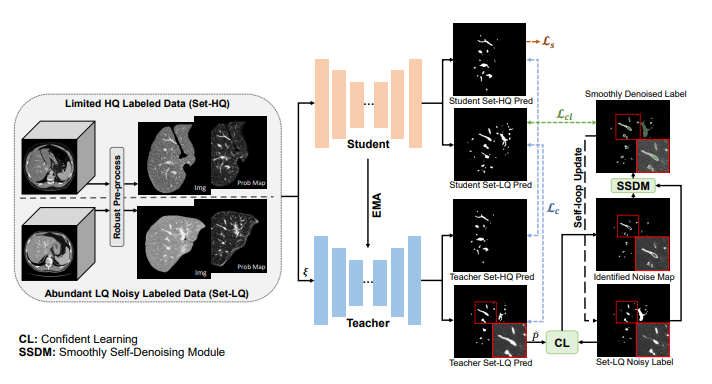
|
- Xu, Z, Lu D, Wang Y, Luo J, Jayender J, Ma K, Zheng Y, Li X†. Noisy labels are treasure:
mean-teacher-assisted confident learning for hepatic vessel
segmentation[C]. In Proceedings of the International
Conference on Medical Image Computing and Computer-Assisted
Intervention (MICCAI-21), 2021, 3-13. WOS:000712019600001. EI Accession number: 20210132011
[Page]
|
|
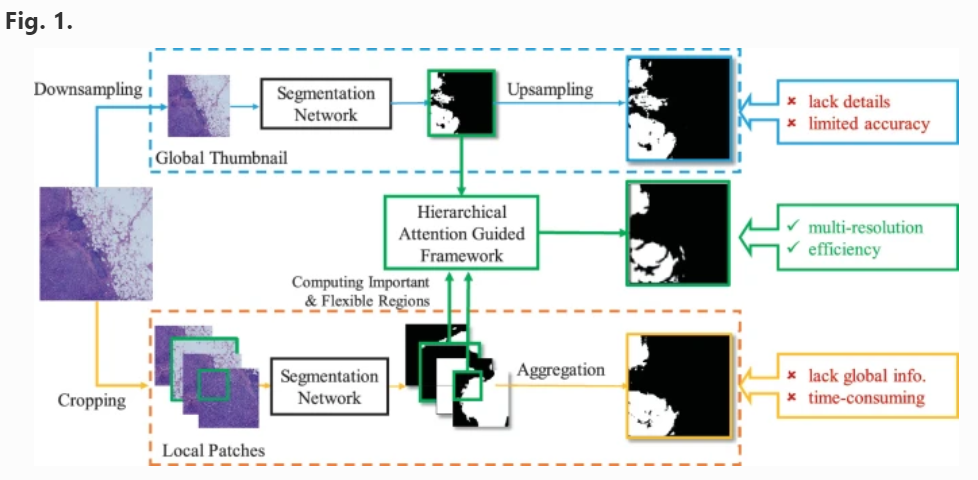
- J Yan, H Chen, K Wang, Y Ji, Y Zhu, J Li, D Xie, Z Xu, J Huang, S Cheng,
X Li†, J Yao. Hierarchical
attention guided framework for multi-resolution collaborative whole
slide image segmentation[C]. In Proceedings of the
International Conference on Medical Image Computing and
Computer-Assisted Intervention (MICCAI-21), 2021:
153-163. WOS:000712019200015. EI Accession number: 20214110994563
[Page]
|

|
- Yu B, Li W, Li X, et al. Frequency-aware spatiotemporal transformers for
video inpainting detection[C]. In Proceedings of the IEEE
International Conference on Computer Vision (ICCV-21).
2021: 8188-8197. WOS:000798743206081. EI Accession number: 20221511951865
[Page]
|
|
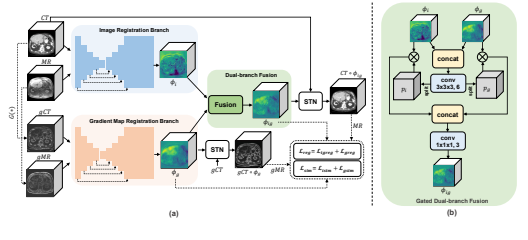
- Xu Z, Yan J, Luo J, Li X, et al. Unsupervised multimodal image registration with
adaptative gradient guidance[C]. In Proceedings of the IEEE
International Conference on Acoustics, Speech and Signal
Processing (ICASSP-21). IEEE, 2021: 1225-1229. INSPEC:20226819. EI Accession number: 20213810914669
[Page]
|
|
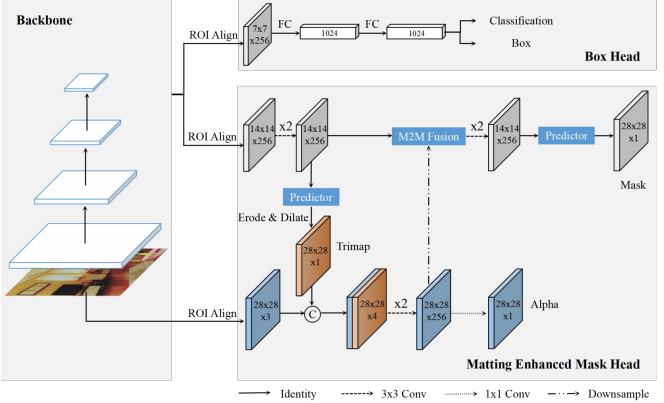
- Ma L, Dong B, Yan J, et al. Matting
enhanced mask R-CNN[C]. In Proceedings of the 2021 IEEE
International Conference on Multimedia and Expo
(ICME-21). IEEE, 2021: 1-6. INSPEC:21761707. EI Accession number: 20221211810228
[Page]
|
|
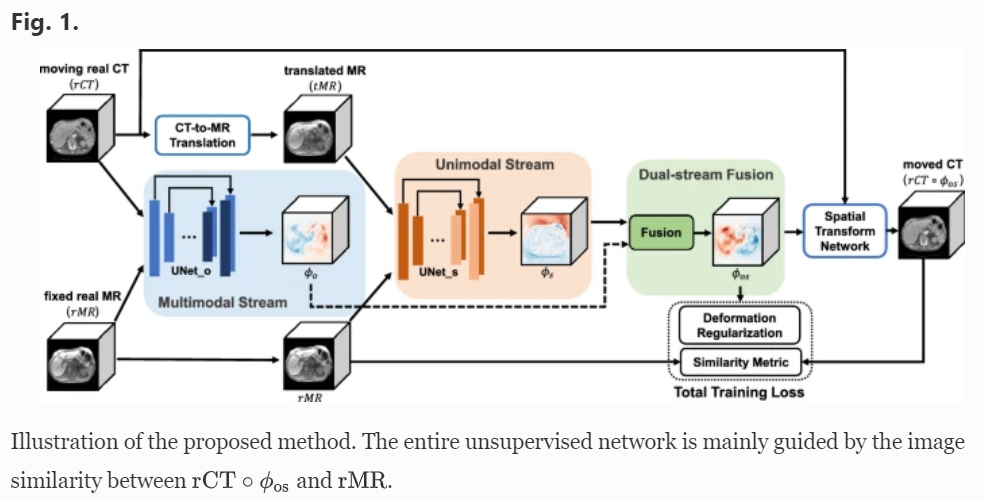
- Xu Z, Luo J, Yan J, Li X,et al. Adversarial uni-and multi-modal stream networks
for multimodal image registration[C]. In Proceedings of
the International Conference on Medical Image Computing and
Computer-Assisted Intervention (MICCAI-20). 2020:
222-232. MEDLINE:33283210. EI Accession number: 20200562212
[Page]
|